《Matching the Blanks: Distributional Similarity for Relation Learning》
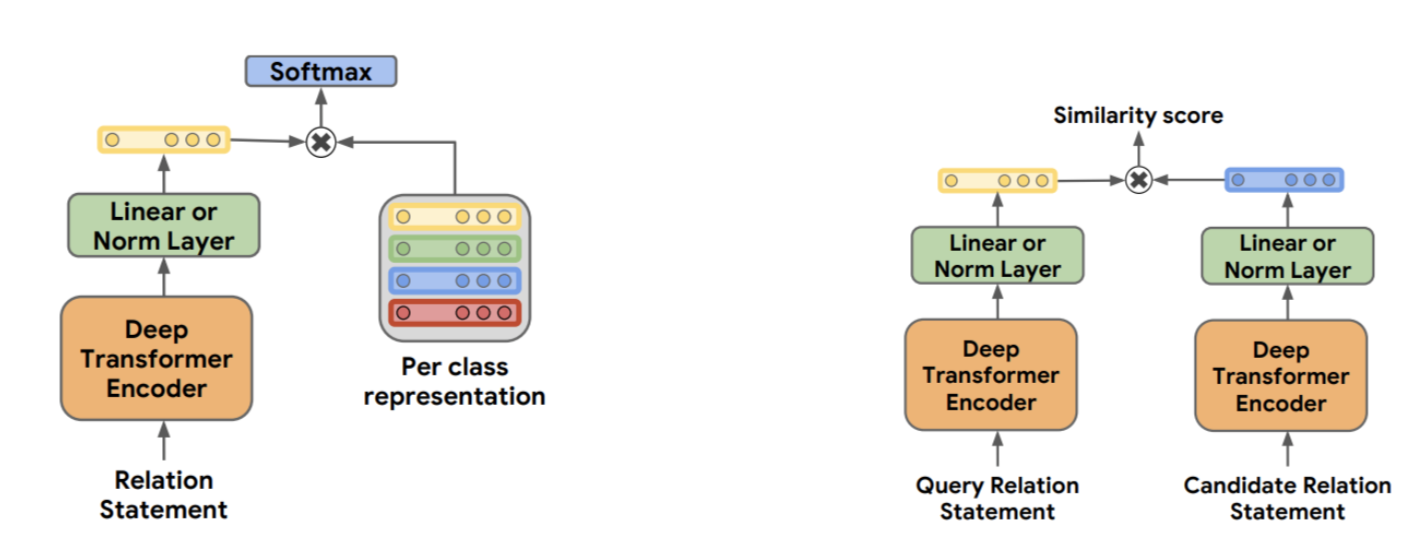
目标:基于大量未标注语料,训练一个relation表征的模型
input:relation statement(x, s1, s2)
output:relation representation: 一个稠密向量,使得两个关系越接近,两个关系的表征向量点积值越大
bert-based architecture:
预训练
- There is high degree for redundancy in web text, relation between tow entity is likely to be stated multiple times
- 两个不同的句子中,如果包含相同的实体对,这个实体对在两句话中大概率表示相同的relation
- 两个不同的句子中,如果包含不同实体对,这两个实体对大概率表示不同的relation
- 例子:

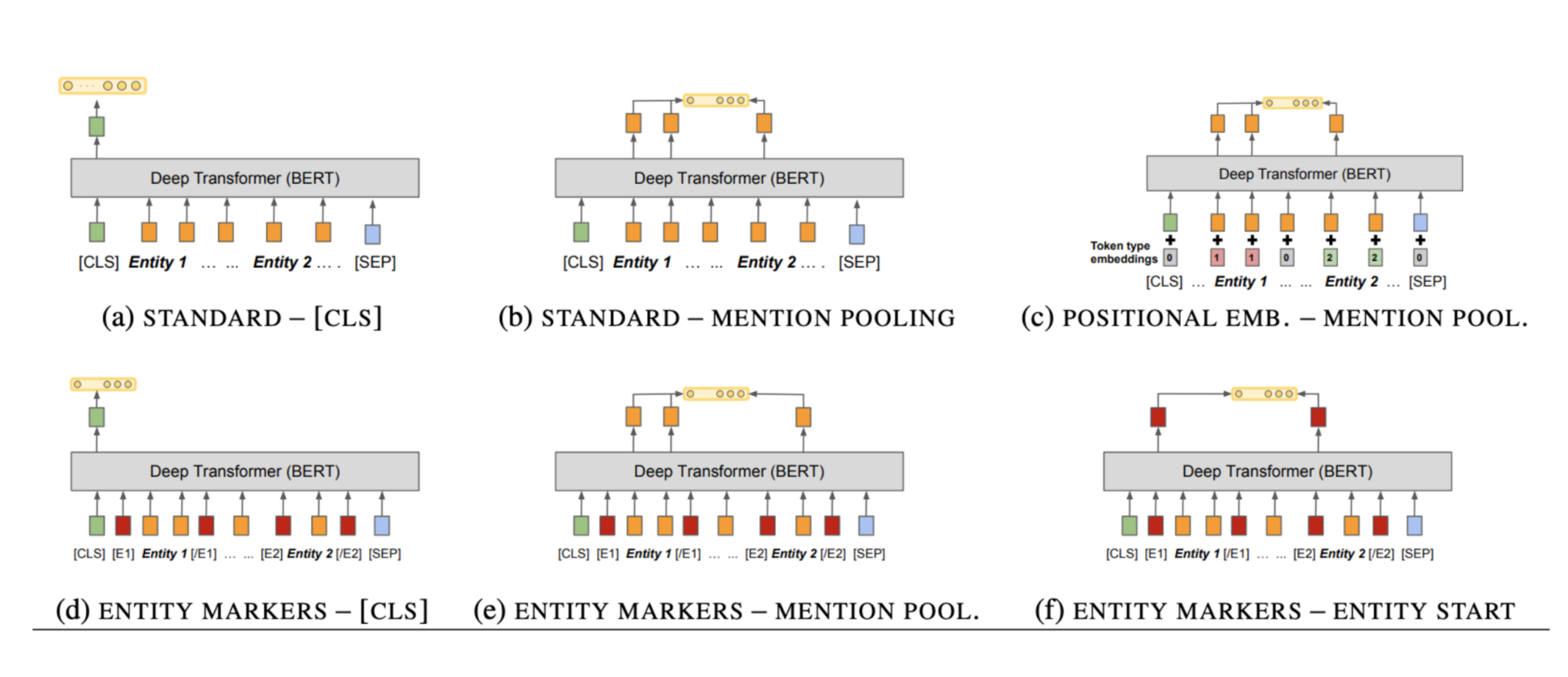
- 结构: