《Neural Open Information Extraction》
- 目标:从输入文本中抽取schema-free的spo三元组
- 模型:
- encoder-decoder的seq2seq模型
- 原文输入encoder,得到一个encoded embedding
- 目标序列格式为
subject predication object - 引入copy机制,从生成的token和copy的token中选择一个
- architecture:
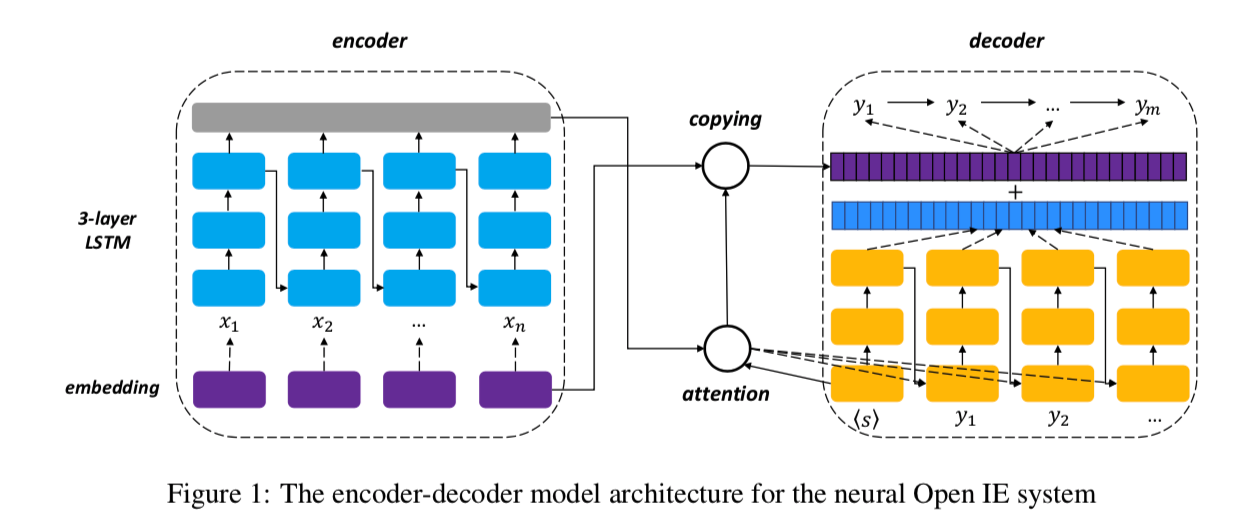
- 实验:
- 数据
- 训练数据从wikipedia的dump构建,36,247,584 pairs,地址:https://1drv.ms/u/s!ApPZx_TWwibImHl49ZBwxOU0ktHv
- 测试数据:3200 sentence with 10369 extractions https://www.aclweb.org/anthology/D16-1252.pdf
- 比较对象:OpenIE4(一个基于规则的提取器)
- 结果:更高的AUC
- 数据