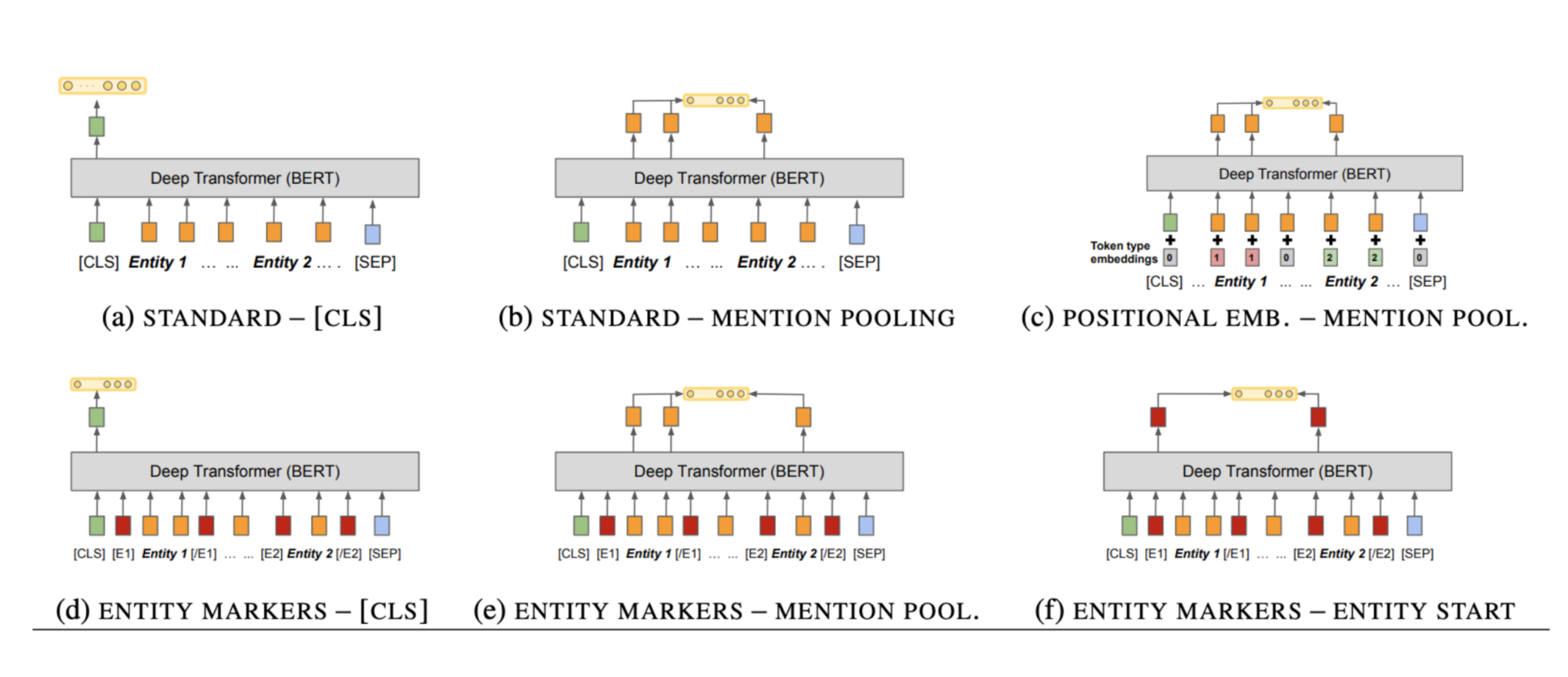
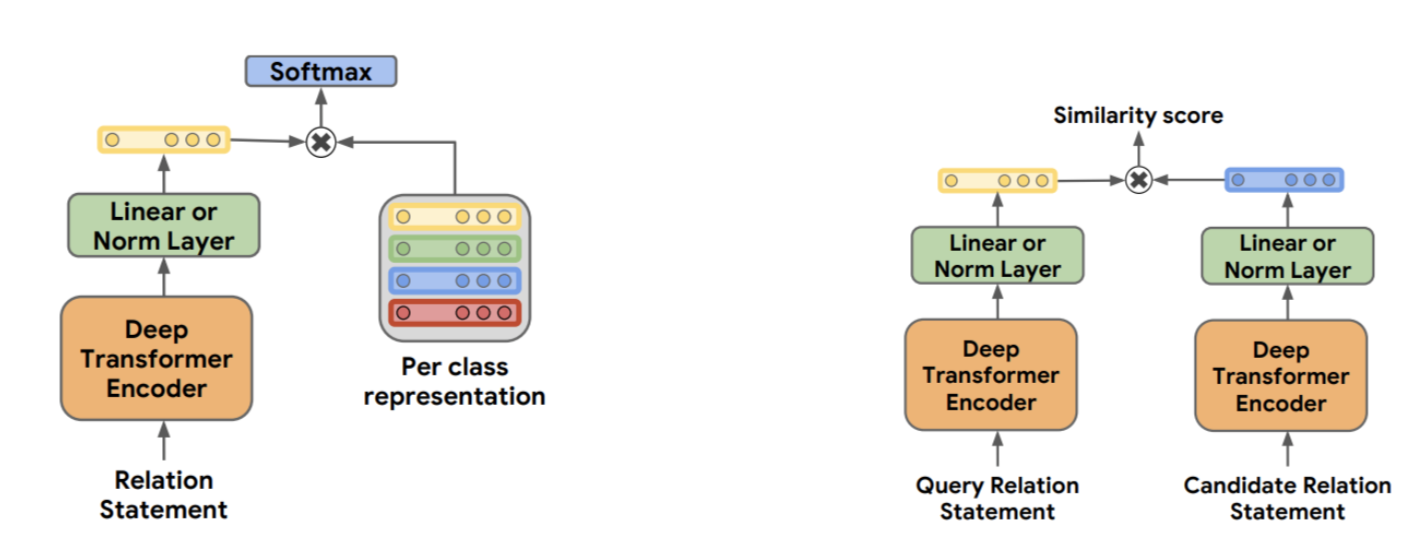
《TPLinker:Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》
解决的问题
给定schema的SPO抽取:从文本中抽取去SPO(Subject-Predicate-Object)三元组。其中Predicate是事先定义好的关系,Subject和Object是文中的span
TPLinker的特点
- 能够处理SEO(SingleEntityOverlap)和EPO(EntityPairOverlap)两种情形
- SEO:张三和李四都是北京人 -> (张三,出生地,北京),(李四,出生地,北京)
- EPO:江苏的省会是南京 -> (江苏,包含,南京),(江苏,省会,南京)
- Single-stage的方案,原始文本过一次Encoder之后,便可以解码得到整个spo三元组