《TPLinker:Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》
解决的问题
给定schema的SPO抽取:从文本中抽取去SPO(Subject-Predicate-Object)三元组。其中Predicate是事先定义好的关系,Subject和Object是文中的span
TPLinker的特点
- 能够处理SEO(SingleEntityOverlap)和EPO(EntityPairOverlap)两种情形
- SEO:张三和李四都是北京人 -> (张三,出生地,北京),(李四,出生地,北京)
- EPO:江苏的省会是南京 -> (江苏,包含,南京),(江苏,省会,南京)
- Single-stage的方案,原始文本过一次Encoder之后,便可以解码得到整个spo三元组
- 消除exposure bias 这个是重点
- pipeline式的抽取模型会有错误传递
- https://kexue.fm/archives/6671 为代表的联合训练抽取S和O的方案,在训练时,预测O依赖的是真实的S信息,在预测时,预测O依赖的是预测出的S信息,造成exposure bias
- 生成式方案:在训练时预测下一个token依赖的是真实的token,预测时预测下一个token依赖的是上一步预测出的token
- 这些方案都会造成在真实预测的效果和在dev集上评测的效果有较大偏差
- TPLinker一步预测出SPO三元组,避免了信息依赖,从而避免了exposure bias
TPLinker的实现方案
- 对每个token pair做分类。对于token pair (t1,t2),我们只考虑t1出现在t2前面的情形,因而长度为N的序列可以构建出一个长度为N*(N+1)/2的token pair序列
- 对于每个实现给定的REL,构建两个label:REL-HH, REL-TT分别表示REL的subject_head和object_head的token pair 以及REL的subject_tail和object_tail的token pair
- 添加一个额外的label:HT,表示subject或者object的head_tail token pair
- 因此,对于K个实现给定的关系,我们能构建出2*K+1个分类标签
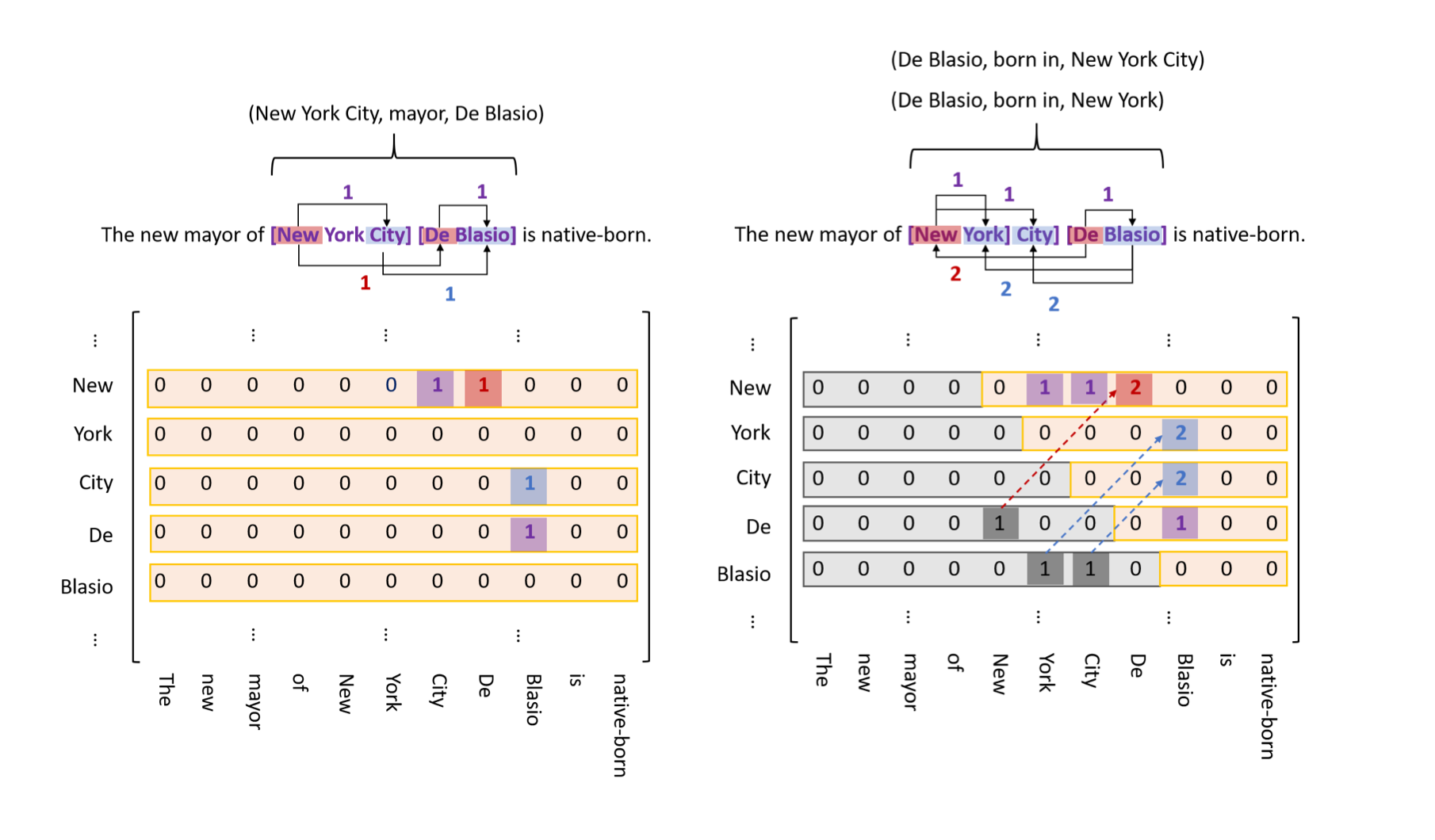
- 对于左图三元组(New York City, mayor, DeBlasio)
- (New, City)的HT标签为1
- (De, Blasio)的HT标签为1
- (New, De)的mayor-HH标签为1
- (City, Blasio)的mayor-TT标签为1
- 对于右图三元组(De Blasio, born in, New York City)
- HT标签同理
- (De, New)的 born in-HH标签为1。由于我们的token pair标志t2在t1后面的情形,所以转化成(New, De)d的born in-HH标签为2
- 模型结构
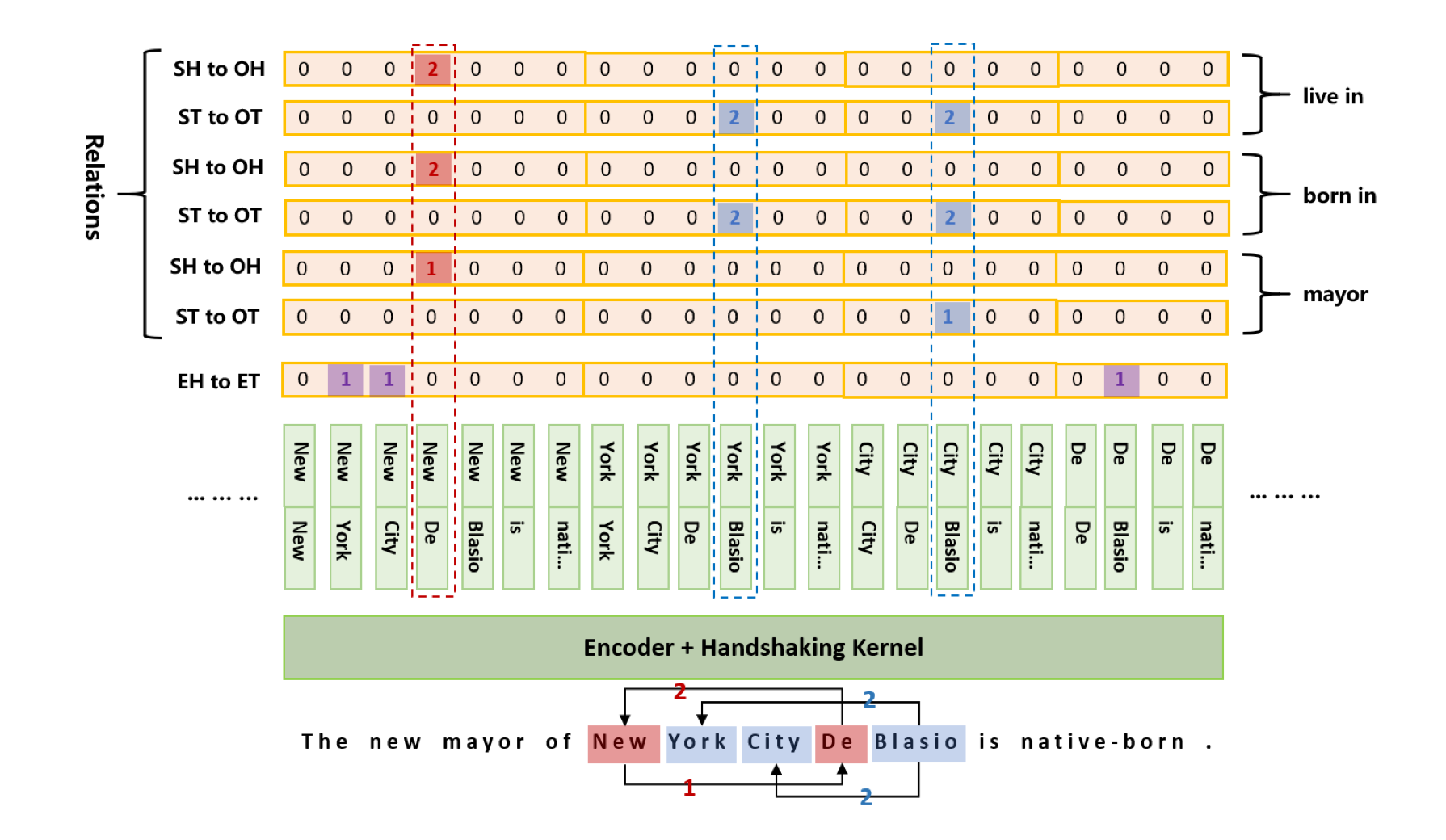
- 解码:HT, HH, TT的标注方式已经可以唯一定位SPO,并且可以表示SEO和EPO的情形。只需要先解码HT标签,找出所有实体的span之后,对于每个REL,解码HH, TT标签后再到实体span中check suject和object范围是否在实体span的列表中即可
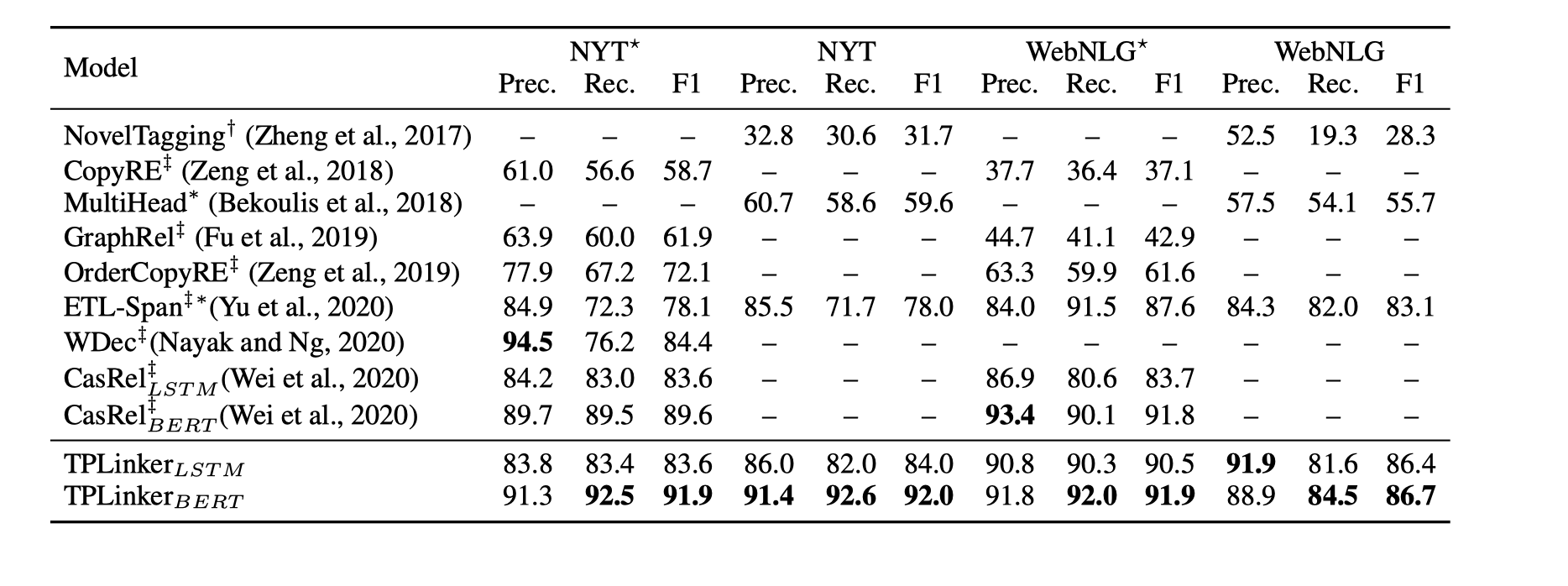
实验
总结
- Single-stage的解码方式可以很好的避免训练过程中的exposure bias。TPlinker提出了一种编码方式,也可以考虑其他的编码方式来做
- Single-stage一般都需要对token pair做排列组合的预测,序列长度平方式增长,因此比较适合短序列的方案
《TPLinker:Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》